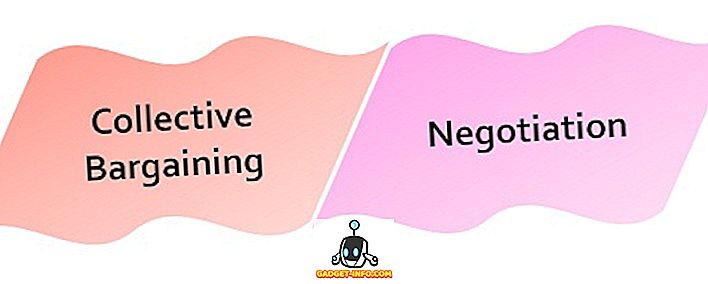
Salīdzinājuma diagramma
| Salīdzināšanas pamats | Klasifikācija | Regresija |
|---|---|---|
| Pamata | Modeļa vai funkciju atklāšana, kur objektu kartēšana tiek veikta iepriekš noteiktās klasēs. | Izstrādāts modelis, kurā objektu kartēšana tiek veikta vērtībās. |
| Ietver prognozes | Diskrētās vērtības | Nepārtrauktas vērtības |
| Algoritmi | Lēmumu koks, loģistiskā regresija utt. | Regresijas koks (nejaušs mežs), lineārā regresija utt. |
| Paredzēto datu veids | Neregulēts | Pasūtīts |
| Aprēķina metode | Mērīšanas precizitāte | Vidējā kvadrāta kļūdas mērīšana |
Klasifikācijas definīcija
Klasifikācija ir process, kurā tiek atrasts vai atklāts modelis (funkcija), kas palīdz atdalīt datus vairākās kategorijās. Klasifikācijā tiek identificēta grupas dalība problēmā, kas nozīmē, ka dati tiek iedalīti dažādās etiķetēs saskaņā ar dažiem parametriem, un pēc tam uzlīmes tiek prognozētas.
Atvasinātos modeļus var demonstrēt “IF-THEN” noteikumu, lēmumu koku vai neironu tīklu veidā utt. Lēmumu koku pamatā ir plūsmas diagramma, kas atgādina koku struktūru, kurā katrs iekšējais mezgls attēlo testu ar atribūtu, un tās filiāles parāda testa rezultātus. Klasifikācijas process risina problēmas, kurās datus var iedalīt divās vai vairākās diskrētās etiķetēs, citiem vārdiem sakot, divos vai vairākos atdalītos komplektos.
Piemēram, pieņemsim, ka mēs vēlamies paredzēt lietus iespēju dažos reģionos, pamatojoties uz dažiem parametriem. Tad būtu divas lietusgāzes un lietus, kur var klasificēt dažādus reģionus.
Regresijas definīcija
Regresija ir process, kurā tiek atrasts modelis vai funkcija, lai atšķirtu datus nepārtrauktās reālās vērtībās, nevis izmantojot klases. Matemātiski ar regresijas problēmu mēģina atrast funkciju tuvināšanu ar minimālo kļūdu novirzi. Regresijā tiek prognozēts, ka datu skaitliskā atkarība to atšķir.
Regresijas analīze ir statistikas modelis, ko izmanto, lai paredzētu ciparu datus etiķešu vietā. Tā var arī noteikt izplatīšanas kustību atkarībā no pieejamajiem datiem vai vēsturiskajiem datiem.
Pieņemsim līdzīgu piemēru arī regresijā, kur dažos konkrētos reģionos ar dažiem parametriem mēs varam atrast lietus. Šādā gadījumā varbūtība ir saistīta ar lietus. Šeit mēs neklasificējam reģionus lietus un bez lietus etiķetēm, bet mēs tos klasificējam ar to saistīto varbūtību.
Galvenās atšķirības starp klasifikāciju un regresiju
- Klasifikācijas process modelē funkciju, ar kuras palīdzību dati tiek prognozēti atsevišķās klases etiķetēs. No otras puses, regresija ir process, kurā tiek veidots modelis, kas paredz nepārtrauktu daudzumu.
- Klasifikācijas algoritmi ietver lēmumu pieņemšanas koku, loģistikas regresiju utt. Turpretī regresijas algoritmu piemēri ir regresijas koks (piemēram, Random forest) un lineārā regresija.
- Klasifikācija paredz neierobežotus datus, kamēr regresija paredz pasūtītos datus.
- Regresiju var novērtēt, izmantojot vidējo kvadrātisko kļūdu. Gluži pretēji, klasifikāciju novērtē, mērot precizitāti.
Secinājums
Klasifikācijas paņēmiens nodrošina prognozēšanas modeli vai funkciju, kas, izmantojot vēsturiskos datus, prognozē jaunos datus atsevišķās kategorijās vai etiķetēs. Un otrādi, regresijas metode modelē nepārtrauktas vērtības funkcijas, kas nozīmē, ka tā prognozē datus nepārtrauktā skaitliskā datu veidā.