


Lai vienkāršotu un / vai standartizētu datu ievadi, Excel izklājlapās bieži ir iekļautas šūnu nolaišanas. Šie nolaižamie saraksti ir izveidoti, izmantojot datu validācijas funkciju, lai norādītu atļauto ierakstu sarakstu.
Lai izveidotu vienkāršu nolaižamo sarakstu, atlasiet šūnu, kurā dati tiks ievadīti, un pēc tam noklikšķiniet uz Datu validācija (cilnē Dati ), atlasiet Datu validācija, izvēlieties Saraksts (sadaļā Atļaut :) un pēc tam ievadiet saraksta vienumus (atdalot ar komatiem ) laukā Source : (skat. 1. attēlu).
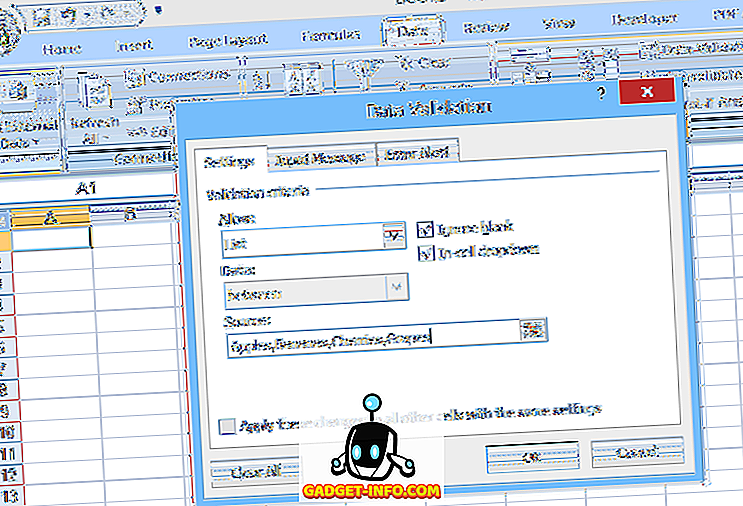
Šāda veida nolaižamajā sarakstā atļauto ierakstu saraksts ir norādīts datu validācijā; tādēļ, lai veiktu izmaiņas sarakstā, lietotājam ir jāatver un jā rediģē datu validācija. Tomēr tas var būt sarežģīti nepieredzējušiem lietotājiem vai gadījumos, kad izvēles saraksts ir garš.
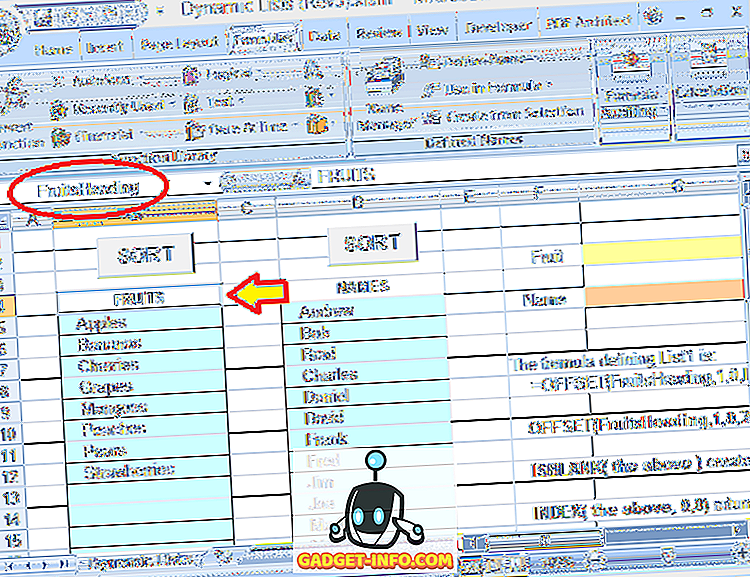
Vēl viena iespēja ir ievietot sarakstu izklājlapā nosauktajā diapazonā un pēc tam norādīt datu diapazona nosaukumu (iepriekš attēlot ar vienādu zīmi) datu validācijas laukā (kā parādīts 2. attēlā).
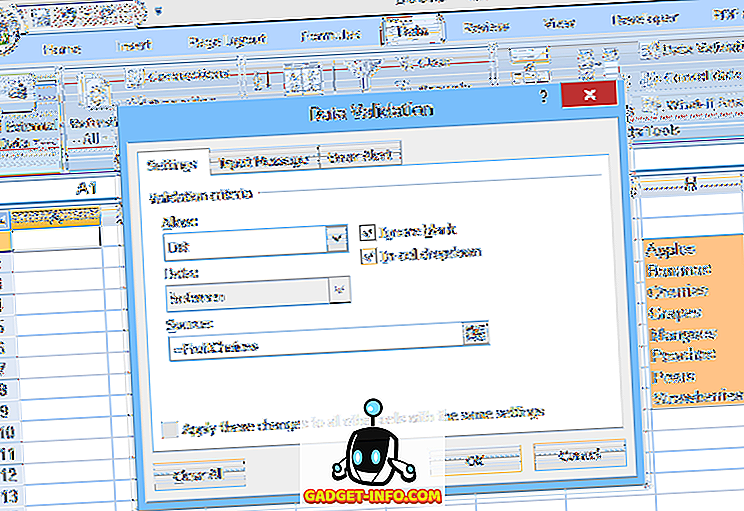
Šī otrā metode atvieglo saraksta izvēles rediģēšanu, bet vienumu pievienošana vai noņemšana var būt problemātiska. Tā kā nosauktais diapazons (FruitChoices, mūsu piemērā) attiecas uz fiksētu šūnu diapazonu ($ H $ 3: $ H $ 10, kā parādīts attēlā), ja šūnām H11 vai zemāk tiek pievienotas vairākas izvēles, tās neatradīsies nolaižamajā (tā kā šīs šūnas nav FruitChoices klāsta daļa).
Tāpat, ja, piemēram, tiek izdzēsti ieraksti „Bumbieri un zemenes”, tie vairs nebūs redzami nolaižamajā izvēlnē, bet nolaižamajā izvēlnē būs divas „tukšas” izvēles, jo nolaižamajā izvēlnē joprojām ir atsauce uz visu FruitChoices diapazonu, ieskaitot tukšās šūnas H9 un H10.
Šo iemeslu dēļ, izmantojot parasto nosaukumu diapazonu kā saraksta avotu nolaižamajam sarakstam, nosauktajam diapazonam jābūt rediģētam, lai tajā iekļautu vairāk vai mazāk šūnu, ja ieraksti tiek pievienoti vai dzēsti no saraksta.
Šīs problēmas risinājums ir izmantot dinamiskā diapazona nosaukumu kā nolaižamās izvēles avotu. Dinamiskā diapazona nosaukums ir tāds, kas automātiski paplašinās (vai slēdz līgumus), lai precīzi atbilstu datu bloka lielumam, jo ieraksti tiek pievienoti vai noņemti. Lai to izdarītu, izmantojiet formulu, nevis fiksētu šūnu adrešu diapazonu, lai definētu nosaukto diapazonu.
Kā iestatīt dinamisko diapazonu programmā Excel
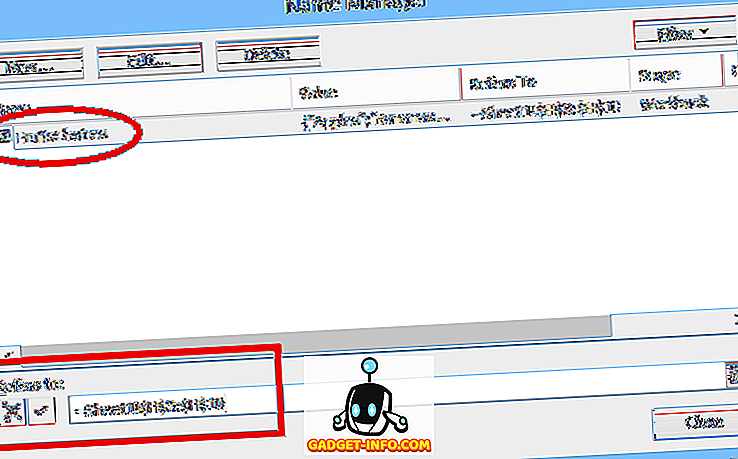
Normāls (statisks) diapazona nosaukums attiecas uz noteiktu šūnu diapazonu ($ H $ 3: $ H $ 10 mūsu piemērā, skatiet tālāk):
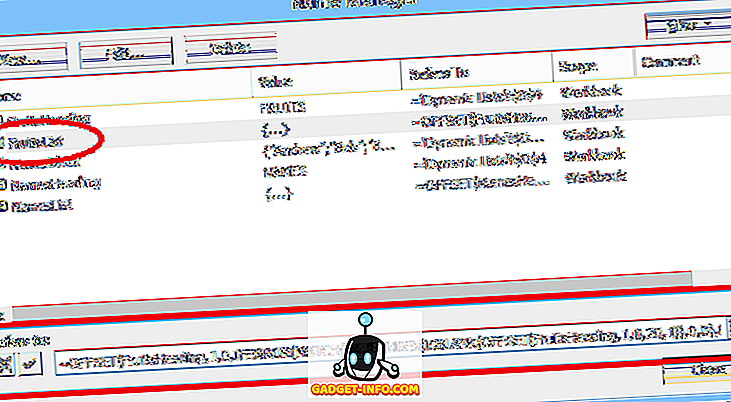
Bet dinamisko diapazonu definē, izmantojot formulu (skat. Tālāk, ņemta no atsevišķas izklājlapas, kurā izmanto dinamiskus diapazona nosaukumus):
Pirms sākam darbu, pārliecinieties, ka lejupielādējat mūsu Excel piemēru failu (kārtot makro ir atspējoti).
Apskatīsim šo formulu detalizēti. Augļu izvēle ir šūnu blokā tieši zem virsraksta ( FRUITS ). Šai pozīcijai piešķirts arī nosaukums: FruitsHeading :
Visa formula, ko izmanto, lai noteiktu augļu izvēles dinamisko diapazonu, ir šāda:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX) (ISBLANK (OFFSET (FruitsHeading, 1, 0, 20, 1)), 0, 0), 0) -1, 20), 1)
FruitsHeading attiecas uz virsrakstu, kas ir viena rinda virs saraksta pirmā ieraksta. Numurs 20 (ko izmanto divas reizes formulā) ir saraksta maksimālais lielums (rindu skaits) (to var pielāgot pēc vajadzības).
Ņemiet vērā, ka šajā piemērā sarakstā ir tikai 8 ieraksti, bet zem tām ir arī tukšas šūnas, kurās var pievienot papildu ierakstus. Numurs 20 attiecas uz visu bloku, kurā var veikt ierakstus, nevis uz faktisko ierakstu skaitu.
Tagad, lai saprastu, kā tā darbojas, iedaliet formulu gabalos (katras daļas krāsu kodēšana):
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX) (ISBLANK ( OFFSET (FruitsHeading, 1, 0, 20, 1) ), 0, 0), 0) -1, 20), 1)
“ Iekšējais ” gabals ir OFFSET (FruitsHeading, 1, 0, 20, 1) . Tas attiecas uz 20 šūnu bloku (zem augļu galvas šūnas), kur var ievadīt izvēli. Šī OFFSET funkcija pamatā saka: Sāciet ar Augļu galvas šūnu, dodieties uz leju 1 rinda un virs 0 slejām, pēc tam atlasiet apgabalu, kas ir 20 rindas garš un 1 kolonna plaša. Tātad tas dod mums 20 rindu bloku, kurā tiek ievadīti augļu izvēle.
Nākamais formulas gabals ir ISBLANK funkcija:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX ( ISBLANK (iepriekš), 0, 0), 0) -1, 20), 1)
Šeit OFFSET funkcija (paskaidrota iepriekš) ir aizstāta ar “iepriekš minēto” (lai padarītu lietas vieglāk lasāmas). Taču ISBLANK funkcija darbojas uz 20 rindu diapazona šūnām, kuras definē OFFSET funkcija.
Tad ISBLANK izveido 20 TRUE un FALSE vērtību kopu, norādot, vai katra atsevišķā šūna 20 rindu diapazonā, uz kuru atsaucas OFFSET funkcija, ir tukša (tukša) vai nav. Šajā piemērā pirmās 8 vērtības komplektā būs FALSE, jo pirmās 8 šūnas nav tukšas un pēdējās 12 vērtības būs TRUE.
Nākamais formulas gabals ir INDEX funkcija:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (augstāk, 0, 0), 0) -1, 20), 1)
Arī "iepriekš" attiecas uz iepriekš aprakstītajām ISBLANK un OFFSET funkcijām. INDEX funkcija atgriež masīvu, kas satur 20 TRUE / FALSE vērtības, ko rada ISBLANK funkcija.
INDEX parasti tiek izmantots, lai izvēlētos noteiktu vērtību (vai vērtību diapazonu) no datu bloka, norādot noteiktu rindu un kolonnu (šajā blokā). Bet rindu un kolonnu ievades iestatīšana uz nulli (kā tas tiek darīts šeit) izraisa INDEX atgriešanos masīvā, kas satur visu datu bloku.
Nākamais formulas gabals ir MATCH funkcija:
= OFFSET (FruitsHeading, 1, 0, IFERROR ( MATCH (TRUE, augstāk, 0) -1, 20), 1)
Funkcija MATCH atgriež pirmās TRUE vērtības pozīciju masīvā, ko atdod INDEX funkcija. Tā kā pirmie 8 ieraksti sarakstā nav tukši, pirmās 8 vērtības masīvā būs FALSE, un devītā vērtība būs TRUE (jo 9. rinda ir tukša).
Tātad MATCH funkcija atgriezīs vērtību 9 . Tomēr šajā gadījumā mēs patiešām vēlamies uzzināt, cik ierakstu ir sarakstā, tāpēc formula atņem 1 no MATCH vērtības (kas dod pēdējā ieraksta pozīciju). Tātad galu galā MATCH (TRUE, iepriekšminētais, 0) -1 atgriež vērtību 8 .
Nākamais formulas gabals ir IFERROR funkcija:
= OFFSET (FruitsHeading, 1, 0, IFERROR (iepriekšminētais, 20), 1)
IFERROR funkcija atgriež alternatīvu vērtību, ja pirmā norādītā vērtība rada kļūdu. Šī funkcija ir iekļauta, jo, ja viss šūnu bloks (visas 20 rindas) ir aizpildīts ar ierakstiem, MATCH funkcija atgriezīs kļūdu.
Tas ir tāpēc, ka mēs stāstām MATCH funkcijai meklēt pirmo TRUE vērtību (ISBLANK funkcijas vērtību rindā), bet, ja NAKTS no šūnām ir tukšas, tad viss masīvs tiks piepildīts ar FALSE vērtībām. Ja MATCH nevar atrast mērķa vērtību (TRUE) meklētajā masīvā, tā atgriež kļūdu.
Tātad, ja viss saraksts ir pilns (un tāpēc MATCH atgriež kļūdu), IFERROR funkcija atgriezīs vērtību 20 (zinot, ka sarakstā jābūt 20 ierakstiem).
Visbeidzot, OFFSET (FruitsHeading, 1, 0, iepriekš minētais, 1) atgriež diapazonu, ko mēs faktiski meklējam: Sākt no FruitsHeading šūnas, dodieties uz 1 rindu un vairāk nekā 0 kolonnām, pēc tam atlasiet apgabalu, kas tomēr ir daudz rindu, kamēr sarakstā ir ieraksti (un 1 sleja). Tādējādi visa formula kopā atgriezīs diapazonu, kas satur tikai faktiskos ierakstus (līdz pirmajai tukšajai šūnai).
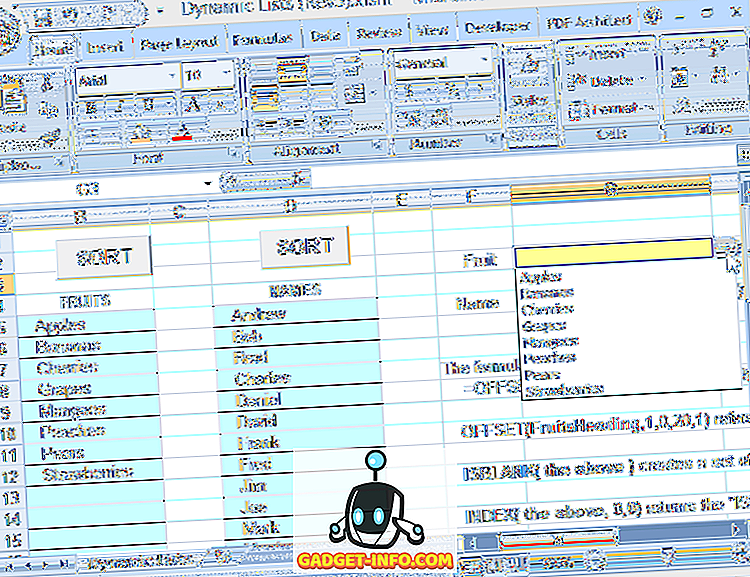
Izmantojot šo formulu, lai noteiktu diapazonu, kas ir nolaižamā avota avots, jūs varat brīvi rediģēt sarakstu (ierakstu pievienošana vai noņemšana, kamēr atlikušie ieraksti sākas augšējā šūnā un ir blakus), un nolaižamais vienmēr atspoguļos pašreizējo sarakstu (sk. 6. attēlu).
Šeit izmantotais piemēru fails (dinamiskie saraksti) ir iekļauts un ir lejupielādējams no šīs tīmekļa vietnes. Makro nedarbojas, jo WordPress nepatīk Excel grāmatas ar makro tiem.
Kā alternatīvu rindu skaita noteikšanai saraksta blokā saraksta blokam var piešķirt savu diapazona nosaukumu, ko pēc tam var izmantot modificētā formātā. Piemēra failā otrajā sarakstā (Vārdi) tiek izmantota šī metode. Šeit visam saraksta blokam (zem virsraksta "NAMES", 40 rindas piemēru failā) tiek piešķirts NameBlock diapazona nosaukums. Pēc tam NamesList definēšanas alternatīvā formula ir:
= OFFSET (NamesHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX) ( ISBLANK ( NamesBlock ), 0, 0), 0) -1, ROWS (NamesBlock) ), 1)
kur NamesBlock aizstāj OFFSET (FruitsHeading, 1, 0, 20, 1) un ROWS (NamesBlock) aizstāj 20 (rindu skaitu) iepriekšējā formulā.
Tātad, nolaižamajos sarakstos, kurus var viegli rediģēt (arī citi lietotāji, kas var būt nepieredzēti), mēģiniet izmantot dinamiskos diapazona nosaukumus! Un ņemiet vērā, ka, lai gan šis raksts ir koncentrēts uz nolaižamajiem sarakstiem, dinamiskos diapazonu nosaukumus var izmantot jebkur, kur nepieciešams atsauce uz diapazonu vai sarakstu, kas var būt atšķirīgs. Izbaudi!






